4. Рад са текстуалним датотекама¶
У овој лекцији:
- уводимо појам текстуалне датотеке;
- објашњавамо како се чита из текстуалне датотеке;
- објашњавамо како се пише у текстуалну датотеку; и
- показујемо како се ради са више датотека.
4.1. Текстуалне датотеке¶
Датотека (или фајл) је произвољно дугачак низ података који се налази на спољашњој меморији, најчешће диску. Постоје разне врсте датотека, а ми ћемо се у овом одељку бавити текстуалним датотекама.
Текстуална датотека је низ симбола као што су слова, бројеви, знаци интерпункције и слично, који се налази на спољашњој меморији. На пример, када у неком едитору као што је Notepad откуцамо неки текст
и када га "снимимо", оперативни систем ће тај текст сместити у текстуалну датотеку на диску.
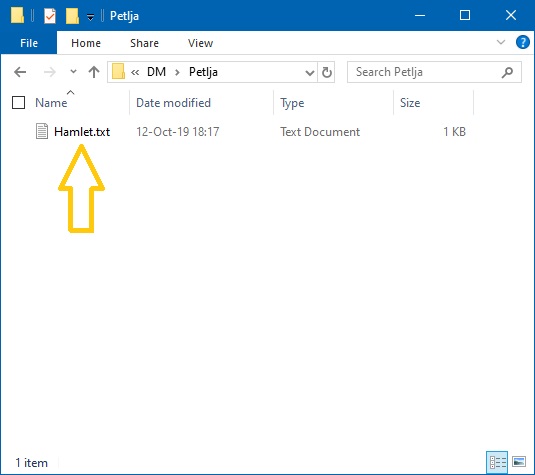
Свака датотека мора да има име, а обичај је да се име датотеке организује тако да последњих неколико симбола у имену означава тип података који је смештен у датотеку. Тај део имена се обично одвоји тачком од остатка имена и зове се екстензија. Текстуалне датотеке обично имају екстензију .txt као у следећем примеру:
Hamlet.txt
Дакле, ова датотека се зове Hamlet.txt, а због екстензије .txt знамо да се ради о текстуалној датотеци коју можемо отворити из програма Notepad, рецимо.
Пре било какве акције са текстуалном датотеком (писање у датотеку или читање из датотеке) она мора да се "отвори", а након акције мора да се "затвори". Као са свеском: да бисмо писали у свеску или читали из свеске морамо прво да је отворимо, а када завршимо морамо да је затворимо. Зато сваки програм који ради са текстуалним датотекама има овакву структуру:
f = open(...) # otvorimo datoteku
... # radimo nešto
... # radimo nešto
f.close() # zatvorimo datoteku
У зависности од тога на који начин је датотека отворена зависиће да ли у њу може да се пише или да се само чита. Свака датотека која се отвори из Пајтона мора да добије име у облику неке променљиве и кроз ту променљиву програм комуницира са датотеком на диску.
Податке из неке датотеке можемо или само да читамо, или је могућ само упис у датотеку. Није могуће истовремено и писати у неку датотеку и читати из ње.
4.2. Читање из текстуалне датотеке¶
У фолдеру podaci налази се текстуална датотека iliad.txt која садржи енглески превод Хомерове Илијаде. Ако отворимо ову датотеку из неког едитора као што је Notepad видећемо да текстуална датотека изгледа као текст који је организован у редове, рецимо овако:
The Project Gutenberg eBook of The Iliad, by Homer
Translated by Edward, Earl of Derby
BOOK I.
Of Peleus' son, Achilles, sing, O Muse,
The vengeance, deep and deadly; whence to Greece
Unnumbered ills arose; which many a soul
Of mighty warriors to the viewless shades
Untimely sent; they on the battle plain
Unburied lay, a prey to rav'ning dogs,
And carrion birds; but so had Jove decreed,
From that sad day when first in wordy war,
The mighty Agamemnon, King of men,
Confronted stood by Peleus' godlike son.
...
Следећа команда отвара ову датотеку за читање:
f = open("podaci/iliad.txt", "r")
Команда open потражи датотеку "podaci/iliad.txt" (што значи да у фолдеру podaci треба потражити датотеку iliad.txt). Аргумент "r" команде open каже Пајтону да датотеку треба припремити за читање (ознака r потиче од првог слова енглеске речи read што значи "читај").
Када смо датотеку припремили за читање, најзгодније је да је прочитамо ред по ред, што се у Пајтону може постићи употребом for циклуса. Команда
for red in f:
# uradimo nešto sa redom
ће читати податке из датотеке f ред по ред:
- програм прочита први ред из датотеке и упише га у променљиву
red; - па изврши тело циклуса;
- онда прочита други ред из датотеке и упише га у променљиву
red; - па изврши тело циклуса;
- и тако за сваки ред датотеке.
На крају не смемо заборавити да затворимо датотеку:
f.close()Пример. У фолдеру podaci налази се текстуална датотека iliad.txt која садржи енглески превод Хомерове Илијаде. Написати Пајтон програм који броји редове у тој датотеци.
Решење.
f = open("podaci/iliad.txt", "r")
br_redova = 0
for red in f:
br_redova += 1
f.close()
print("Datoteka iliad.txt ima", br_redova, "redova")
Пример. У фолдеру podaci налази се текстуалнa datoteka iliad.txt којa садржи енглески превод Хомерове Илијаде. Пошто је Илијада веома дугачак спев Хомер га је поделио у делове које је звао Књиге (у давна времена када је писмених људи било веома мало обичај је био да се свака мало дужа писана форма зове књига, слично као у народној песми: "Па он одмах ситну књигу пише/Те је шаље цару у Стамбола").
Написати Пајтон програм који утврђује из колико делова/књига се састоји Илијада. Почетак књиге је означен редом који изгледа овако:
BOOK ...
(да се подсетимо, радимо са енглеским преводом Илијаде, па се књиге зову "book").
Решење.
f = open("podaci/iliad.txt", "r")
br_knjiga = 0
for red in f:
if red[:4] == "BOOK":
br_knjiga += 1
f.close()
print("Homerova Ilijada ima", br_knjiga, "knjige")
Пример. Написати Пајтон програм који утврђује колико се пута у Хомеровој Илијади помиње Ахил, а колико пута Хектор. Пошто радимо са енглеским преводом Илијаде у тексту тражимо речи "Achilles" и "Hector".
Решење 1. За решење нам је потребна функција prebroj_podstr(p, s) из претходног поглавља која утврђује колико се пута стринг p јавља као подстринг стринга s. Онда прођемо datoteku ред по ред и пребројимо колико се пута у том реду јављају имена ова два јунака.
def prebroj_podstr(p, s):
broj = 0
n = len(p)
for i in range(len(s) - n + 1):
if p == s[i:i+n]:
broj += 1
return broj
f = open("podaci/iliad.txt", "r")
br_ahil = 0
br_hektor = 0
for red in f:
br_ahil += prebroj_podstr("Achilles", red)
br_hektor += prebroj_podstr("Hector", red)
f.close()
print("Ahil se pominje", br_ahil, "puta")
print("Hektor se pominje", br_hektor, "puta")
Решење 2. Ако су датотеке са којима радимо релативно мале (а то зависи од количине меморије коју имамо) могуће је функцијом read() учитати целу датотеку у меморију као један велики стринг. Тада је довољно у том великом стрингу пребројати колико се пута јављају имена легендарних јунака.
def prebroj_podstr(p, s):
broj = 0
n = len(p)
for i in range(len(s) - n + 1):
if p == s[i:i+n]:
broj += 1
return broj
f = open("podaci/iliad.txt", "r")
ceo_tekst = f.read()
f.close()
print("Ahil se pominje", prebroj_podstr("Achilles", ceo_tekst), "puta")
print("Hektor se pominje", prebroj_podstr("Hector", ceo_tekst), "puta")
4.3. Читање сложенијих података представљених текстуалним датотекама¶
Као што смо већ видели, постоје разни формати за табеларно представљање података, а најједноставнији од њих се зове CSV, (од енгл. comma separated values што значи "вредности раздвојене зарезима"). Интересантно је да је CSV датотека је текстуална датотека у којој редови одговарају редовима табеле, а подаци унутар истог реда су раздвојени зарезима. На пример, у фолдеру podaci се налази датотека Top 25 YouTubers.csv која изгледа овако:
RANK,GRADE,NAME,VIDEOS,SUBSCRIBERS,VIEWES
1,A++,T-Series,13629,105783888,76945588449
2,A,PewDiePie,3898,97853589,22298927681
3,A+,5-Minute Crafts,3341,58629572,14860695079
4,A++,Cocomelon - Nursery Rhymes,441,53163816,33519273951
...
25,A,TheEllenShow,10542,33362512,16519572219
Ова табела садржи податке о 25 најпопуларнијих Јутјубера према броју претплатника на дан 1.7.2019. Први ред табеле представља заглавље табеле које нам каже да табела има шест колона (RANK, GRADE, NAME, VIDEOS, SUBSCRIBERS, VIEWES). Врста
4,A++,Cocomelon - Nursery Rhymes,441,53163816,33519273951
значи да је на дан 1.7.2019. четврти по реду био Јутјуб канал са Јутјуб рангом А++ који се зове "Cocomelon - Nursery Rhymes" који је објавио укупно 441 видео на Јутјубу, који има 53.163.816 претплатника и 33.519.273.951 прегледа.
Када прочитамо један ред ове датотеке (осим првог реда, наравно!) добићемо један стринг у коме су подаци раздвојени зарезима. Да бисмо могли да анализирамо податке који су уписани у ред треба нам начин да "разбијемо" ред на појединачне податке. Томе слуши функција split() чије име потиче од енглеске речи split што значи "раздвој".
На пример, нека је
red = "4,A++,Cocomelon - Nursery Rhymes,441,53163816,33519273951"
Када напишемо:
s = red.split(",")
променљива функција split ће разбити стринг red на делове који су у стрингу раздвојени зарезима, и променљива s ће тада бити низ стрингова:
s
Сада можемо лако приступити сваком елементу овог низа.
Све време, међутим, треба водити рачуна о томе да функција split враћа низ стрингова, па ако неки од њих представља број, да бисмо од стринга направили одговарајући број треба користити уграђене функције int или float.
Пример. У фолдеру podaci се налази датотека Top 25 YouTubers.csv која садржи податке о 25 најпопуларнијих Јутјубера према броју претплатника на дан 1.7.2019. Први ред табеле представља заглавље табеле које нам каже да табела има шест колона (RANK, GRADE, NAME, VIDEOS, SUBSCRIBERS, VIEWES).
Написати Пајтон програм који чита податке из ове датотеке и одређује који од ових 25 канала је објавио највише видеа.
Решење. Први ред у датотеци представља заглавље табеле и њега треба да прескочимо. То можемо постићи функцијом readline() која прочита један ред из датотеке. Зато одмах након отварања датотеке наредбом
red = f.readline()
прочитамо и одбацимо први ред. For циклус који следи наставља да чита датотеку ред по ред. Сваком учитани ред прво разбијемо на појединачне податке позивом функције split(","), а онда из добијеног низа стрингова читамо елементе који нас занимају. Конкретно, s[2] садржи име канала, док s[3] представља стринг репрезентацију броја објављених видеа. Да бисмо овај податак добили у облику броја која можемо поредити са другим бројевима користимо функцију int овако: int(s[3]).
f = open("podaci/Top 25 YouTubers.csv", "r")
red = f.readline() # prvi red predstavlja zaglavlje tabele i njega preskacemo
br_vid = 0
naj_kanal = ""
for red in f:
s = red.split(",")
if int(s[3]) > br_vid:
br_vid = int(s[3])
naj_kanal = s[2]
f.close()
print("Najvise videa je objavio kanal", naj_kanal)
4.4. Писање у текстуалну датотеку¶
Када желимо нешто да упишемо у текстуалну датотеку морамо је прво припремити за уписивање тако што је отворимо овако:
f = open("pesmica.txt", "w")
или овако:
f = open("pesmica.txt", "а")
Ако датотеку отворимо на први предложени начин, аргумент "w" команде open каже Пајтону да датотеку треба припремити за писање (ознака w потиче од првог слова енглеске речи write што значи "пиши"). Пајтон ће припремити датотеку за упис података, а ако је можда у систему постојала датотека са истим именом њен садржај ће бити избрисан! Дакле, open("pesmica.txt", "w") ће отворити нову, празну датотеку и спремити је за упис података.
Ако датотеку отворимо на други начин, аргумент "a" команде open каже Пајтону да датотеку треба припремити за додавање новог садржаја на крај постојеће датотеке (ознака a потиче од првог слова енглеске речи append што значи "доддај"). Пајтон ће припремити датотеку за упис података тако што ће је отворити и нови садржај ће бити дописан иза постојећег садржаја. Дакле, open("pesmica.txt", "a") ће отворити датотеку и спремити је за додавање података иза онога што већ пише у датотеци. Ако датотека са наведеним именом не постоји у систему, Пајтон ће отворити нову празну датотеку и припремити је за упис.
У текстуалну датотеку уписујемо податке командом write, на пример овако:
f.write("Tekst koji se upisuje u datoteku")
Командом write у датотеку можемо да уписујемо само стрингове. Ако желимо да у датотеку упишемо неку другу врсту података, он прво мора бити конвертована у стринг позивом уграђене функције str.
Када завршимо уписивање, датотеку затварамо као и раније позивом команде close, на пример овако:
f.close()Пример. У датотеку "pitagora.txt" уписати чувену интерпретацију Питагорине теореме Душка Радовића:
Kvadrat nad hipotenuzom,
to zna svako dete,
jednak je zbiru kvadrata
nad obe katete.
Решење 1.
f = open("pitagora.txt", "w")
f.write("Kvadrat nad hipotenuzom,")
f.write("to zna svako dete,")
f.write("jednak je zbiru kvadrata")
f.write("nad obe katete.")
f.close()
Ако сада погледамо шта је уписано у датотеку, рецимо користећи програм Notepad, видећемо да ствари нису баш онакве како смо из замислили:
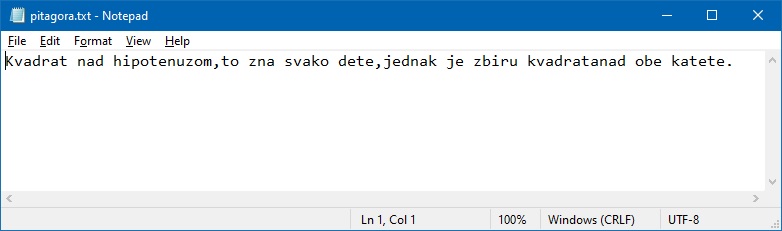
Све је уписано у исти ред!
Наредба write уписује податке у датотеку, али све смешта у исти ред. Да бисмо прешли у нови ред морамо то експлицитно да нагласимо тако што ћемо на крај сваког реда додати специјални симбол:
\n
Овај симбол спада у посебну класу контролних симбола који се не виде када погледамо текстуалну датотеку из програма као што је Notepad, али им говоре да на том месту треба прећи у нови ред. Слово "n" је одабрано за име овог контролног симбола зато што је то прво слово енглеске речи newline што значи "нови ред". Специјални симбол испред слова "n" (обрнута коса црта) значи да се ради не о латиничном слову "n" већ о контролном сиболу чије име је "n". Ево сада исправног решења.
Решење 2.
f = open("pitagora.txt", "w")
f.write("Kvadrat nad hipotenuzom,\n")
f.write("to zna svako dete,\n")
f.write("jednak je zbiru kvadrata\n")
f.write("nad obe katete.\n")
f.close()
Ако сада погледамо шта је уписано у датотеку добићемо:
као што смо и желели. Приметимо да је други позив наредбе open("pitagora.txt", "w") прво обрисао стару датотеку!
Пример. Написати програм који у текстуалну датотеку pesmica.txt уписује чувену дечију песмицу "Ten Little Monkeys":
10 little monkeys were jumping on a bed
one fell off and bumped its head.
Mommy called the doctor and the doctor said:
'No more monkeys jumping on the bed!'
9 little monkeys were jumping on a bed
one fell off and bumped its head.
Mommy called the doctor and the doctor said:
'No more monkeys jumping on the bed!'
...
2 little monkeys were jumping on a bed
one fell off and bumped its head.
Mommy called the doctor and the doctor said:
'No more monkeys jumping on the bed!'
1 little monkey was jumping on a bed
it fell off and bumped its head.
Mommy called the doctor and the doctor said:
'Put those monkeys back to bed!'
Решење.
Приметимо да првих девет строфа има исту структуру и да је једина разлика међу њима број којим строфа почиње. Десета строфа, с друге стране, има потпуно другачију структуру. Зато ћемо првих девет строфа генерисати у цинклусу, док ћемо десету строфу исписати посебно.
f = open("pesmica.txt", "w")
for i in range(9):
f.write(str(10 - i) + " little monkeys were jumping on a bed\n")
f.write("one fell off and bumped its head.\n")
f.write("Mommy called the doctor and the doctor said:\n")
f.write("'No more monkeys jumping on the bed!'\n")
f.write("\n")
# poslednja strofa
f.write("1 little monkey was jumping on a bed\n")
f.write("it fell off and bumped its head.\n")
f.write("Mommy called the doctor and the doctor said:\n")
f.write("'Put those monkeys back to bed!'\n")
f.close()
4.5. Рад са више датотека истовремено¶
Пајтон програм може да ради са више датотека истовремено. Важно је да свакој датотеци буде додељена њена променљива и онда систем лако зна шта у коју датотеку треба да се упише. Такав програм има овакву структуру:
f = open(...) # otvorimo prvu datoteku
g = open(...) # otvorimo drugu datoteku
... # radimo nešto
... # radimo nešto
f.close() # zatvorimo prvu datoteku
g.close() # zatvorimo drugu datotekuПример. Написати Пајтон програм који у датотеку podaci/duzine.txt уписује дужине редова из датотеке podaci/iliad.txt.
Решење. Подсетимо се да командом write у датотеку можемо да уписујемо само стрингове. Ако је потребно да у датотеку упишемо неку другу врсту података, он прво мора бити конвертована у стринг позивом уграђене функције str. Специјални симбол \n означава крај реда, тако да ће бројеви бити уписани сваки у посебан ред.
f = open("podaci/iliad.txt", "r")
g = open("podaci/duzine.txt", "w")
for red in f:
n = len(red)
g.write(str(n) + "\n")
f.close()
g.close()
Пример. Датотеке podaci/BOOK01.txt, podaci/BOOK02.txt, ..., podaci/BOOK12.txt садрже првих дванаест књига енглеског превода Хомерове Илијаде. Ових првих дванаест књига чине први део Илијаде. Написати Пајтон програм који их спаја у једну датотеку под именом iliad_vol1.txt. Прва два реда у датотеци треба да гласе:
The Project Gutenberg eBook of The Iliad, by Homer
Translated by Edward, Earl of Derby
Поред тога, између сваке две књиге треба оставити два празна реда. На крај треба додати ред
END OF VOLUME I.
Решење. Пошто треба да надовежемо низ датотека, основну датотеку ћемо отворити за писање употребом параметра "a" (што је скраћено од "append" -- додај на крај).
vol1 = open("podaci/iliad_vol1.txt", "a")
vol1.write("The Project Gutenberg eBook of The Iliad, by Homer\n")
vol1.write("Translated by Edward, Earl of Derby\n")
vol1.write("\n")
vol1.write("\n")
datoteke = ["podaci/BOOK01.txt", "podaci/BOOK02.txt", "podaci/BOOK03.txt", "podaci/BOOK04.txt",
"podaci/BOOK05.txt", "podaci/BOOK06.txt", "podaci/BOOK07.txt", "podaci/BOOK08.txt",
"podaci/BOOK09.txt", "podaci/BOOK10.txt", "podaci/BOOK11.txt", "podaci/BOOK12.txt"]
for dat in datoteke:
f = open(dat, "r");
s = f.read()
vol1.write(s)
vol1.write("\n")
vol1.write("\n")
f.close()
vol1.write("END OF VOLUME I.\n")
vol1.close()
4.6. Задаци¶
Задатак 1. У фолдеру podaci налази се текстуалнa datoteka iliad.txt којa садржи енглески превод Хомерове Илијаде. Написати Пајтон програм који одређује колико у овој датотеци има слова која нису празнине, ни специјални симболи.
Задатак 2. У фолдеру podaci налази се текстуалнa datoteka iliad.txt којa садржи енглески превод Хомерове Илијаде. Написати Пајтон програм који одређује колико речи има у овој датотеци.
Задатак 3. Написати Пајтон програм који упоређује две текстуалне датотеке и исписује први ред у које је детектована разлика. Програм треба да испише редни број тог реда, као и сам ред.
Задатак 4. У фолдеру podaci налази се текстуалнa datoteka iliad.txt којa садржи енглески превод Хомерове Илијаде. Написати Пајтон програм који ову датотеку преписује у нову која се зове iliad-num.txt у којој сваки непразан ред има свој број, рецимо овако:
1. The Project Gutenberg eBook of The Iliad, by Homer
2. Translated by Edward, Earl of Derby
3. BOOK I.
4. Of Peleus' son, Achilles, sing, O Muse,
5. The vengeance, deep and deadly; whence to Greece
6. Unnumbered ills arose; which many a soul
7. Of mighty warriors to the viewless shades
8. Untimely sent; they on the battle plain
9. Unburid lay, a prey to rav'ning dogs,
10. And carrion birds; but so had Jove decreed,
11. From that sad day when first in wordy war,
12. The mighty Agamemnon, King of men,
13. Confronted stood by Peleus' godlike son.
14. ...Задатак 5. у тексуталној датотеци podaci/brojevi.txt налази се више редова текста, а сваки ред се састоји из низа бројева раздвојених зарезима. Написати Пајтон програм који чита ову датотеку и у текстулану датотеку brojevi-izlaz.txt уписује, ред по ред, збирове бројева из сваког реда. Дакле, први ред датотеке brojevi-izlaz.txt садржи само један број који је збир бројева из првог реда датотеке podaci/brojevi.txt и тако редом.
Задатак 6 У фолдеру podaci налази се текстуалнa datoteka iliad.txt којa садржи енглески превод Хомерове Илијаде. Написати Пајтон програм који ову датотеку преписује у нову која се зове iliad-num5.txt у којој сваки пети непразан ред има свој број, рецимо овако:
The Project Gutenberg eBook of The Iliad, by Homer
Translated by Edward, Earl of Derby
BOOK I.
Of Peleus' son, Achilles, sing, O Muse,
5. The vengeance, deep and deadly; whence to Greece
Unnumbered ills arose; which many a soul
Of mighty warriors to the viewless shades
Untimely sent; they on the battle plain
Unburid lay, a prey to rav'ning dogs,
10. And carrion birds; but so had Jove decreed,
From that sad day when first in wordy war,
The mighty Agamemnon, King of men,
Confronted stood by Peleus' godlike son.
...Задатак 7. Датотеке podaci/BOOK01.txt, podaci/BOOK02.txt, ..., podaci/BOOK12.txt садрже првих дванаест књига енглеског превода Хомерове Илијаде. Написати Пајтон програм који утврђује која од ових дванаест књига има највише речи, као и о ком броју речи се ради.
Задатак 8. Датотеке podaci/BOOK01.txt, podaci/BOOK02.txt, ..., podaci/BOOK12.txt садрже првих дванаест књига енглеског превода Хомерове Илијаде. Написати Пајтон програм који за сваку од првих дванаест књига у датотеку iliad-books.txt уписује колико речи има у тој књизи. Подаци о свакој књизи се уписују у посебан ред.